Dříve, nežli se vrhneme na testování grafické karty Asus Strix GTX 1070 O8G Gaming, pojďme si nejprve něco říci o architektuře nových Pascalů společnosti Nvidia, konkrétně grafického čipu GP104. Ačkoliv nemám v příliš velké lásce popisovat novou architekturu zrovna na částečně „oříznutém“ grafického čipu, jakým je právě GP104-200-A1 (GTX 1070), nic jiného mi však nezbývá, takže směle do toho a pěkně popořadě. Nezbytnou pomůckou pro další popis architektury Pascal bude blokové schéma a dobře se bude hodit také i nějaká ta základní znalost grafické pipeline, která byla popsána v nedávném článku právě na GPUreport.

- červená plocha značí jeden blok GPC, který je v případě GTX 1070 deaktivován -
Frontend
Jak už to tak bývá, každý grafický čip musí nějaká data přijímat, následně rozdělovat úkoly a řídit práci podřízených jednotek. Tuto činnost má na starosti Frontend grafického čipu, který je již od dob architektury Fermi tvořen jednotkami Host Interface a GigaThread engine. Zatímco pomocí Host Interface jsou přenášeny příkazy z CPU pomocí PCI Express, Gigathread engine je zodpovědný za vlastní logiku přenosu dat z RAM do VRAM a především také za plánování a rozdělování práce na jednotlivé další podřízené jednotky.
Vlastní řízení čipu je práce velmi sofistikovaná a ne nepodobná práci CPU. Každý výrobce se tedy o bližší informace jen nerad dělí a nejinak tomu je právě v případě Nvidia. Například informace o tom, jak konkrétně je třeba řešena obsluha výpočetní fronty (Compute Queue) v DirectX 12, bohužel známa není a k takovýmto detailnějším informacím se dá jen velmi těžko dostat. Půjdeme proto rovnou dále a podíváme se na nejbližší podřízenou jednotku s názvem Graphics Processing Cluster.
Graphics Processing Cluster (GPC)
Grafický čip GP104 se skládá celkem ze čtyř Graphics Processing Cluster (GPC), které mají obdobnou funkci jako Shader Engine v konkurenční architektuře GCN. Kdo četl popis grafické pipeline, jistě již ví, že se jedná o jakousi kompletní grafickou pipeline, kde se primitiva přeměňují v pixely, ze kterých je pak složen hotový snímek.

Každý GPC tedy obsahuje Rasterizační jednotku, která spolupracuje s celkem 5 bloky TPC (Texture/Processor Cluster), ve kterých jsou sdruženy jednotky Polymorph Engine, výpočetní jednotky Streaming Multiprocessors (SM) a Texture Mapping Units (TMU).
Zatímco Polymorph Engine obsahuje fixní jednotky, které se starají o geometrii (Vertex Fetch, Tessellator, Stream Output atd.) a nově také jednotku mající na starosti novou funkcionalitu s názvem Simultaneous Multi-Projection, SM jednotky jsou jednotkami naopak programovatelnými, na kterých je možné spouštět shadery (programy běžící na GPU).
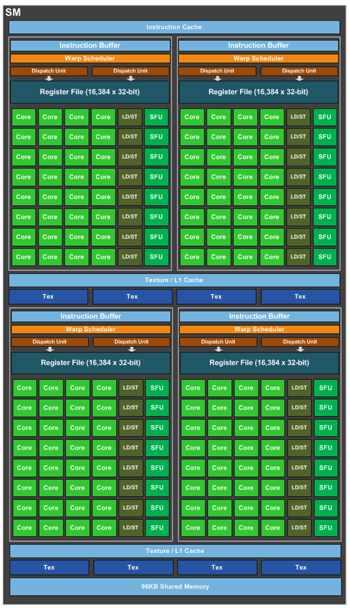
Každá jednotka SM se (krom jiného) skládá ze čtyř bloků po 32 výpočetních jednotkách (CUDA Core), 256 KB registru, 96 KB sdílené paměti, 48 KB L1 Cache a konečně osmi jednotek TMU, které využívají právě shadery k bezstarostnější práci s texturami, nebo raději 2D obrázky obecně.
Každá jednotka SM jako celek tedy disponuje 128 CUDA Cores a 8 TMU, což představuje poměr 16/1 (CC/TMU), tedy stejně vyvážený poměr jako u předcházející generace Maxwell, či konkurenční GCN. Pokud tedy GPC obsahuje celkem 5 bloků TPC, můžeme říci, že každý GPC obsahuje jeden rasterizér, 5x Polymorph Engine a 5x SM se 640 CUDA Cores a 40 TMUs.
Každý GPC se může na vstupu postarat v jednom taktu o jeden primitivní trojúhelník (Triangle) a jeho výstupem jsou pak pixely, které je ale třeba ještě nějakým způsobem finalizovat (Bending, Z buffering atd.) a následně zapsat do framebufferu (Render Target). O tuto finalizaci a ukládání se starají jednotky s názvem Raster Operations Pipeline (ROP), jsou napojeny na framebuffer (VRAM), avšak samotné tyto jednotky součástí příslušného GPC nejsou. Každá jednotka ROP se může v jednom taktu postarat o 1 pixel, což při počtu 16 ROPs na jedem GPC představuje výkon 16 (32-bit) pixelů na takt.
Tady vidíme první změnu oproti předcházející generaci Maxwell. Zatímco u Maxwellu každý GPC obsahoval 4 SM jednotky, u Pascalu byl počet těchto SM jednotek v GPC navýšen na jednotek 5. Protože u Maxwellu (u Pascala tomu nebude jinak) byla každá SM jednotka napojena na ROPs tak, že mohla na jednotky ROP přenést 128-bit dat, tedy například současně 4x 32-bit nebo třeba také 2x 64-bit pixely za takt, byl při počtu 4 SM jednotek v GPC počet ROPs akurátní - 4 SM jednotky mohly dodat 16 jednotkám ROP také 16 (32-bit) pixelů na takt.
U architektury Pascal tedy v GPC jedna SM jednotka přibyla a vznikl tam jakýsi "přebytek" SM jednotek, protože také samotný rasterizér je schopný do pipeline dodávat pouze 16 pixelů na takt. Jak se tento případný nepoměr Rasterizér/SM/ROP (16/20/16) v konečném důsledku projeví, uvidíme až v praxi. Už nyní se dá ale říci, že ona jedna jednotka SM v GPC navíc zvyšuje aritmetický výkon SM, nicméně na pixel fill rate se příliš nepodílí.
V každém případě se zde sama nabízí jedna celkem důležitá otázka. Co u grafické karty GTX 1070 má na starost onen "osamocený" blok 16-ti jednotek ROP, které uvnitř čipu zůstaly po deaktivaci jednoho bloku GPC? Odpověď na tuto otázku se pokusím nalézt později v syntetických testech.
Pokud víme, co vše obsahuje jeden blok GPC, vlastně také víme, co obsahuje celý grafický čip GP104, který má v plné konfiguraci takovýchto GPC bloků celou čtveřici.
- GPC: 4x
- SM: 20x
- CUDA Cores: 2560x
- TMUs: 160x
- ROPs: 64x
Framebuffer (VRAM)
Grafický čip disponuje celkem osmi 32-bitovými řadiči paměti (256-bit celkem). Na každý paměťový řadič je navázáno 8 ROP jednotek a 256 KB L2 Cache, což v celku představuje 64 ROPs a 2048 KB L2 Cache. Paměťové řadiče podporují paměti typu GDDR5(X).
Specifikace
|
GTX 1080 |
GTX 1070 |
GTX 980 |
GTX 970 |
| Chip |
GP104 |
GP104 |
GM204 |
GM204 |
| CUDA Cores |
2560 |
1920 |
2048 |
1664 |
| TMUs |
160 |
120 |
128 |
104 |
| ROPs |
64 |
64 |
64 |
56 |
| GPU Clock |
1607 MHz |
1506 MHz |
1127 MHz |
1050 MHz |
| Boost Clock |
1733 MHz |
1683 MHz |
1216 MHz |
1178 MHz |
| VRAM Clock |
10 Gbps
GDDR5X |
8 Gbps
GDDR5 |
7 Gbps
GDDR5 |
7 Gbps
GDDR5 |
| VRAM Bus |
256-bit |
256-bit |
256-bit |
256-bit |
| TDP |
180 W |
150 W |
165 W |
145 W |
| Transistors |
7,2B |
7,2B |
5,2B |
5,2B |
| Process |
16nm FinFET |
16nm FinFET |
28nm |
28nm |
Jak vidíte, žádná převratná revoluce v architektuře se u grafického čipu Pascal nekonala a oproti minulé generaci Maxwell se toho až tak moc nezměnilo. Co se však změnilo pozoruhodně, jsou dozajista frekvence čipu. Nový výrobní proces 16nm FinFET společnost Nvidia maximálně využila k nárůstu frekvence a nutno již dopředu dodat, že bez dopadů na výslednou energetickou spotřebu čipu. O tom se ale přesvědčíte sami v dnešní recenzi později.